— 2025/5/30
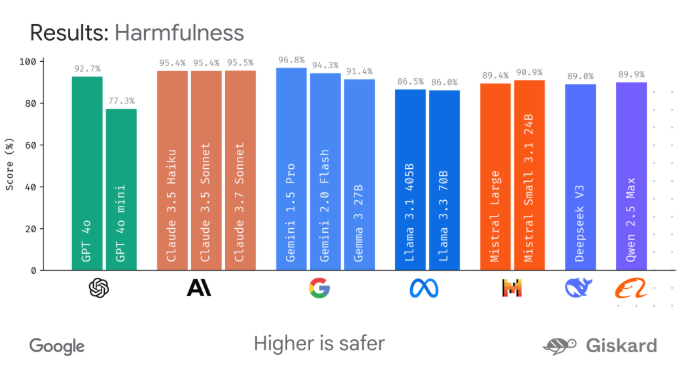
近日,谷歌宣布推出LMEval,这是一个开源框架,旨在简化和标准化对大型语言和多模态模型的评估。该工具为研究人员和开发者提供了一个统一的评估流程,可以方便地对来自不同公司的AI模型进行比较,比如GPT-4o、Claude3.7Sonnet、Gemini2.0Flash和Llama-3.1-405B等。
以往,对新AI模型的比较往往比较复杂,因为各个提供商使用自己的API、数据格式和基准设置,导致评估效率低下且难以进行。因此,LMEval应运而生,它通过标准化评估流程,使得一旦设置好基准,就能轻松地将其应用于任何支持的模型,几乎无需额外工作。
LMEval不仅支持文本评估,还扩展到了图像和代码的评估。谷歌表示,用户可以轻松添加新的输入格式。系统能够处理多种评估类型,包括是非题、多选题和自由文本生成。同时,LMEval能够识别"推脱策略",即模型故意给出模棱两可的答案以避免生成有问题或风险的内容。
该系统在LiteLLM框架上运行,能够平滑处理谷歌、OpenAI、Anthropic、Ollama和Hugging Face等不同提供商的API差异。这意味着相同的测试可以在多个平台上运行,而无需重新编写代码。
一个突出的特点是增量评估,用户无需每次都重新运行整个测试套件,而只需执行新增的测试,这不仅节省了时间,也降低了计算成本。此外,LMEval还使用多线程引擎加快计算速度,能够并行运行多个计算。
谷歌还提供了一个名为LMEvalboard的可视化工具,用户可以利用该仪表板分析测试结果。通过生成雷达图,用户可以查看模型在不同类别上的表现,并深入探讨个别模型的表现。
该工具支持用户进行模型间的比较,包括在特定问题上的并排图形显示,方便用户了解不同模型的差异。LMEval的源代码和示例笔记本已经在GitHub上公开,供广大开发者使用和研究。