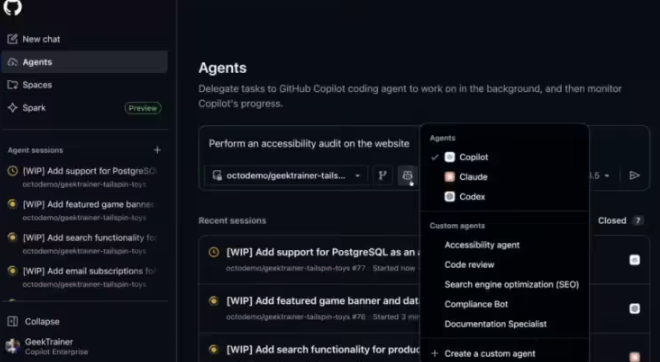
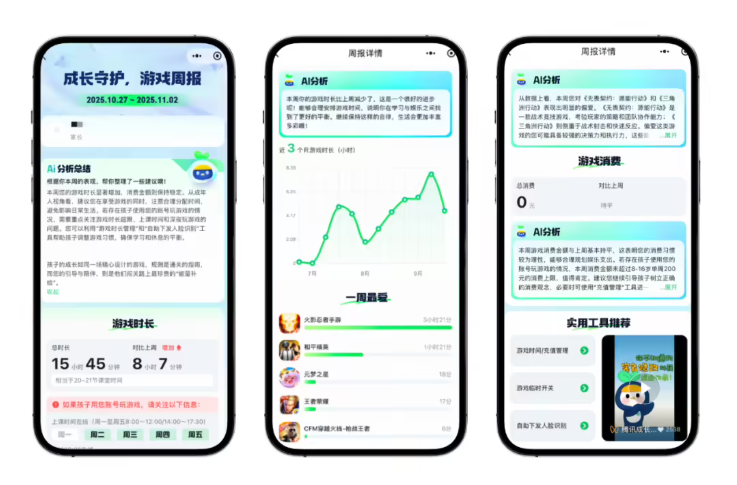
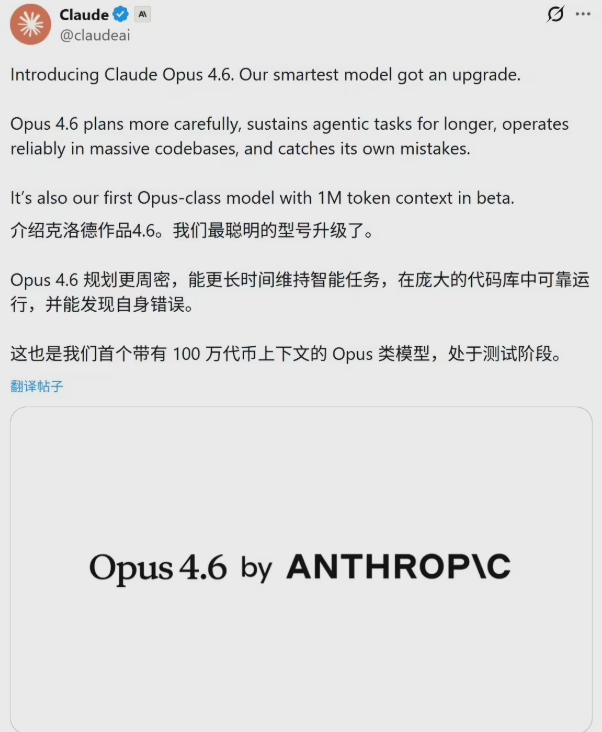
— 2025/07/04
OmniGen2的核心是一个基于Qwen2.5-VL-3B变换器的大型多模态语言模型(MLLM)。在图像生成方面,该系统使用了一种自定义的扩散变换器,参数量达到约40亿。模型在遇到特殊的"<|img|>"标记时会自动切换到图像生成模式,实现了文本与图像生成的无缝切换。

值得一提的是,OmniGen2能够处理多种提示和艺术风格,展现出强大的创作灵活性。尽管其生成的照片级图像在清晰度上仍有待提升,但在艺术创作和概念设计方面已展现出令人印象深刻的能力。
为了训练OmniGen2,研究团队使用了大约1.4亿张来自开源数据集和专有集合的图像。此外,他们还开发了新技术,通过提取视频中的相似帧(例如,一个微笑和不微笑的面孔),并利用语言模型生成相应的编辑指令,这种创新的数据生成方法大大丰富了训练素材的多样性。
OmniGen2的另一大亮点是其反思机制,能够让模型自我评估生成的图像,并在多个轮次中进行改进。该系统可以发现生成图像中的缺陷,并提出具体的修正建议,这种自我优化能力使得最终输出质量得到显著提升。
为了评估该系统的性能,研究团队引入了OmniContext基准测试,包括角色、物体和场景三大类,每类下有八个子任务和各50个示例。评估是通过GPT-4.1进行的,主要打分标准包括提示的准确性和主题的一致性。OmniGen2的总分为7.18,超越了所有其他开源模型,而GPT-4o的得分为8.8。
这一成绩表明,OmniGen2在开源多模态生成领域已达到领先水平,为研究人员和开发者提供了强有力的工具选择。相比其他开源解决方案,OmniGen2在图像生成质量和文本理解能力方面都展现出明显优势。
尽管OmniGen2在多个基准测试中表现优异,但仍存在一些不足之处:英文提示的效果优于中文,身体形态的变化较为复杂,输出质量也受到输入图像的影响。对于模糊的多图像提示,系统需要明确的对象放置指示才能产生理想效果。
研究团队计划将模型、训练数据和构建管道发布到Hugging Face平台,这将进一步推动开源多模态人工智能技术的发展。随着技术的持续优化和社区的积极参与,OmniGen2有望在图像生成、内容创作和人工智能应用等领域发挥更大价值。