— 2025/6/6
近期,科技领军企业英伟达与麻省理工学院(MIT)、香港大学联合发布了革命性的Fast-dLLM框架。这一突破性技术专门针对扩散模型(Diffusion-based LLMs)的推理速度优化,实现了高达27.6倍的性能提升,为人工智能领域带来了强劲的技术驱动力。
扩散模型作为传统自回归模型的强力竞争对手,采用双向注意力机制,理论上能够通过多词元同步生成来加速解码流程。然而,在实际部署中,扩散模型的推理效率往往不如自回归模型,主要原因在于每个生成步骤都需要重新计算完整的注意力状态,造成计算资源的大量消耗。
此外,多词元并行解码过程中,词元之间的依赖关系容易受到破坏,进而影响最终的生成品质。这些技术瓶颈限制了扩散模型在实际应用中的推广和普及。
为了攻克上述技术难题,英伟达研发团队开发了Fast-dLLM框架,并引入了两项关键技术创新:块状近似KV缓存机制和置信度感知并行解码策略。
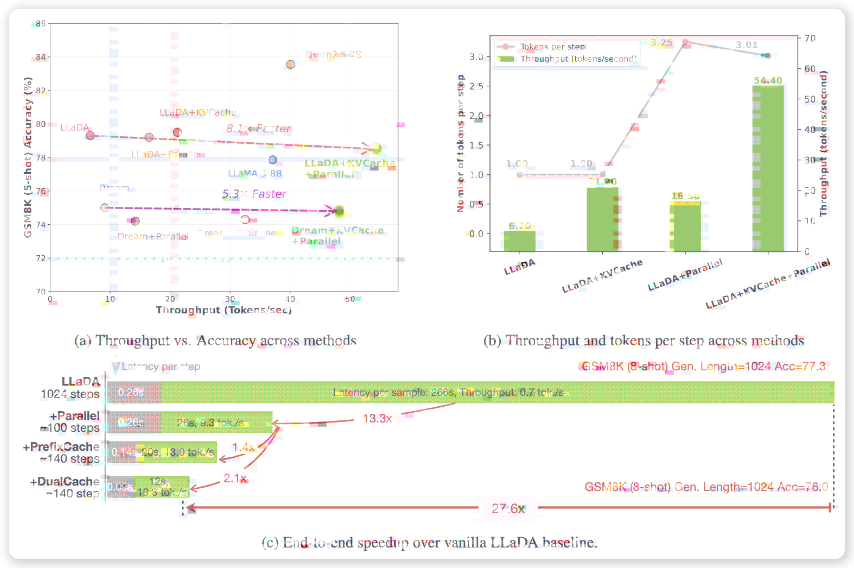
块状近似KV缓存机制:该技术通过将序列分割为多个数据块(Blocks),提前计算并存储各个块的激活值(KV Activations),在后续的解码过程中实现重复利用。这种设计方案大幅减少了计算冗余,显著提升了处理效率。其升级版本DualCache进一步缓存前后缀词元(Prefix and Suffix Tokens),充分利用相邻推理步骤之间的高度相似性来提升处理速度。
置信度感知并行解码策略:该策略基于预设的置信度阈值(Confidence Threshold),有选择性地解码高置信度词元,有效避免了同步采样导致的依赖冲突问题,从而确保生成内容的质量稳定性。
Fast-dLLM在多个权威基准测试中展现出卓越的性能表现。在GSM8K数据集测试中,当生成长度达到1024词元时,其8-shot配置实现了27.6倍的速度提升,准确率高达76.0%。
在MATH基准测试中,该框架实现了6.5倍的加速效果,准确率约为39.3%。在HumanEval和MBPP代码生成测试中,分别达到了3.2倍和7.8倍的加速表现,准确率分别维持在54.3%和基线水平附近。
综合来看,Fast-dLLM在大幅提升推理速度的同时,准确率仅下降1-2个百分点,成功实现了速度与质量之间的最佳平衡。
通过有效解决推理效率和解码质量的核心问题,Fast-dLLM使扩散模型在实际语言生成任务中具备了与自回归模型正面竞争的技术实力,为未来更广泛的商业应用打下了坚实基础。
随着这一突破性技术的逐步推广应用,我们有理由期待人工智能在更多垂直领域实现深度落地,为各行各业带来更高效、更智能的解决方案。